Synq Labs
Research & engineering as one discipline. We build the infrastructure layer for enterprise AI - and publish how.
Three active research programs.
Enterprise Context Capture
activeHow to systematically extract, encode, and maintain enterprise knowledge in machine-queryable form. Covers ingestion methodology, knowledge graph construction, and temporal decay.
Agentic Data Infrastructure
activeBuilding data infrastructure that improves as agents use it. Self-improving context stores, feedback loops, active learning from agent outcomes.
Applied Enterprise AI
activeDeploying LLMs in real enterprise environments - expert reasoning encoding, domain-specific fine-tuning, evaluation frameworks for business outcomes.
research area - agentic data infrastructure
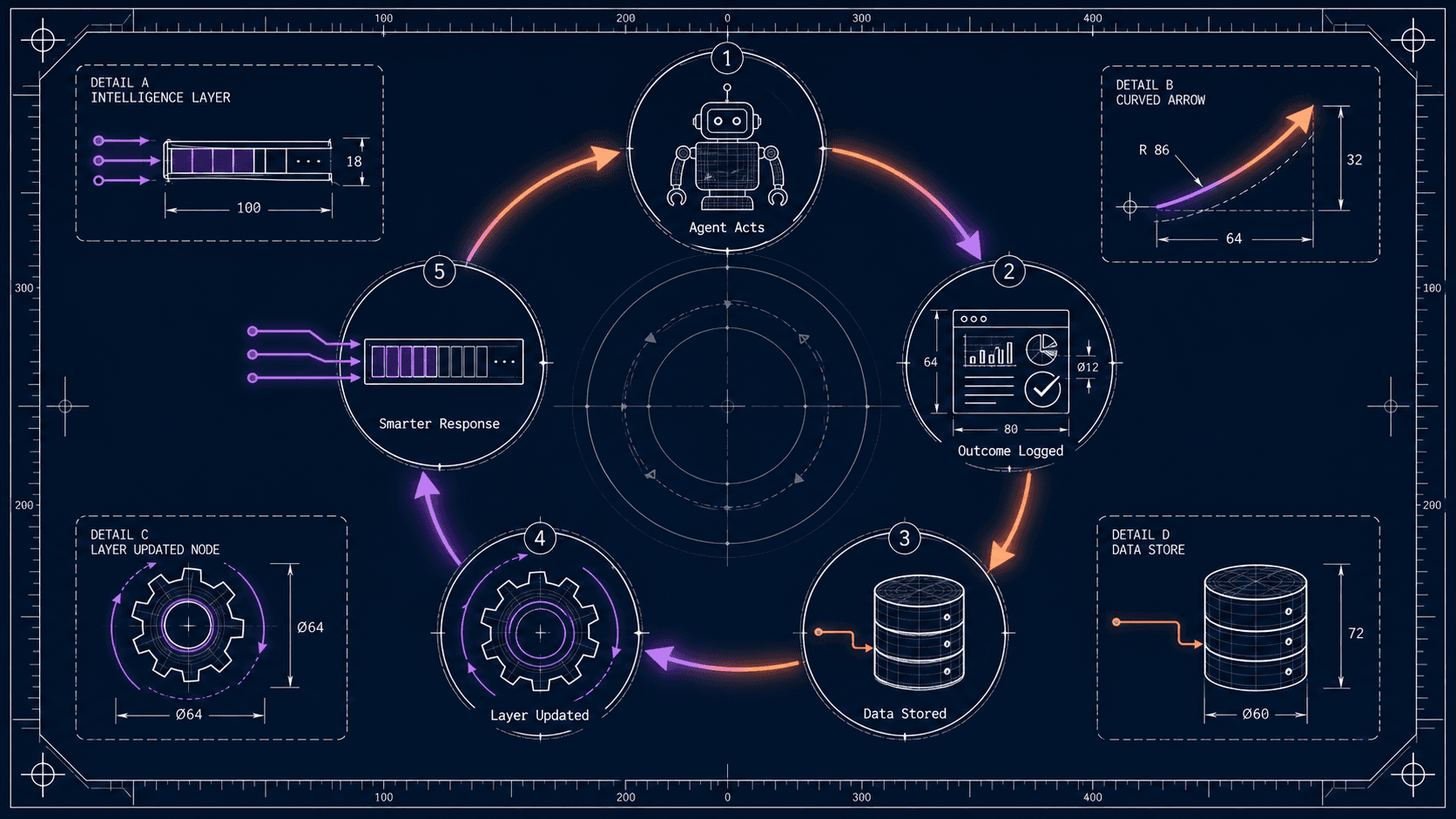
The Self-Improvement Feedback Loop
Every agent action generates outcome data that feeds back into the context layer - logged, stored, and used to sharpen future responses. The architecture compounds in accuracy and capability automatically over time, without manual retraining.
We publish because building in secret is how bad AI gets deployed at scale.
Every pattern in our research came from a real deployment - a real enterprise, a real problem, a real failure or win. We document them not because it helps our brand, but because the field needs more production evidence and less academic speculation. These are not position papers. They're field notes.
Research
// research - 04 papers
India Defense AI Infrastructure: Sovereign LLMs, DefenseLlama, and the Architecture Gap
India's defense AI ecosystem has crossed from policy intent into capital deployment. With ₹7.85 lakh crore allocated in FY26-27 and the operational validation of AI systems like Akashteer during Operation Sindoor, the questions have shifted from 'should we build?' to 'how do we build it sovereignly?' This paper maps the current state of India's defense AI infrastructure, identifies the critical gap in sovereign LLM capability, and benchmarks India's position against the US, China, and Israel.
India Defense AI: Tactical Edge Deployment & Operational AI
If the first paper in this series addressed India's defense AI infrastructure at the strategic and institutional level, this paper addresses what happens at the operational edge - where soldiers, sailors, and pilots interact with AI systems in contested, degraded, and time-critical environments. The key finding: India has demonstrated significant AI capability in controlled or semi-controlled environments (air defense, maritime surveillance), but tactical edge deployment - where compute is constrained, connectivity is intermittent, and latency is lethal - remains an unsolved challenge.
The Context Layer: Why Enterprise AI Fails Without Institutional Memory
Enterprise AI has a deployment problem, not a capability problem. Foundation models from Anthropic, OpenAI, Google, and Meta are technically capable of performing the reasoning tasks enterprises need - drafting, analysis, decision support, workflow automation. They fail not because the models are weak, but because they lack the institutional context to make their outputs trustworthy in a specific enterprise environment. This paper characterizes the nature of this context gap, surveys why existing approaches (RAG, fine-tuning, structured prompting) fail to close it, and proposes the Context Layer as the necessary architectural addition.
The Type 3 Workflow Data Gap: Why Enterprises Can't Automate What They Can't Capture
The most valuable enterprise data is the data that enterprises are worst at capturing: the workflow data embedded in human judgment, exception handling, and expert decision-making. This paper introduces a taxonomy for enterprise workflow data, characterizes the Type 3 Workflow Data gap across three high-value enterprise processes, and argues that the economics of AI agent deployment have fundamentally changed the value of capturing this data.
Enterprise data no one else has.
All datasets are anonymized, enterprise-consented, and licensed under commercial agreements. Contact us for access terms.
// from the field
Notes from deploying AI inside real enterprises.
Not theory. Not predictions. Things we've actually seen, measured, and learned.
Why Every Enterprise AI Pilot Fails
The failure isn't in the model. It's in the missing context layer that every enterprise AI deployment needs to succeed.
Read →India's 1,800 GCCs Are Sitting on the Most Valuable AI Training Data in the World
Global Capability Centers process the world's enterprise workflows. The data they generate is the rarest dataset in AI - and no one's capturing it systematically.
Read →Build with us.
We publish research and share methods. If you're working on enterprise AI infrastructure, we want to hear from you.